会計処理のAI利用でブラックボックスが発生しないようにするために
「AIを利用するのは便利ですが、その部分がブラックボックス化するのは、会計処理として不都合です。『なぜ、そう仕訳したのか分かりません』というわけにはいかないのです」と深堀さん。
そこで『処理の透明性を確保しながら、効率化を実現する』領収書の仕訳処理フローを考えたとのこと。PwCで、同社が担当する超大企業のシリアスな会計処理や経理処理の文化を体験し、マネーフォワードで開発を経験し、そして現在自身の税理士事務所で、現実的に処理を省力化したいというニーズがある深堀さんだからこそ作れたワークフローだともいえる。
先に概要を説明すると、このワークフローはScanSnapとClaude(クロード)AIのふたつのOCRを連携、突き合わせ処理してその2つに差違があるところにフラグが立ち、そこは原本を視認チェックするという仕組みになっている。視認チェックするのは手間だが会計処理としての正確さを求めるとこうなるということだ。
ScanSnapを使って、高度なファイル名を作るのがキモ
詳しく説明していこう。
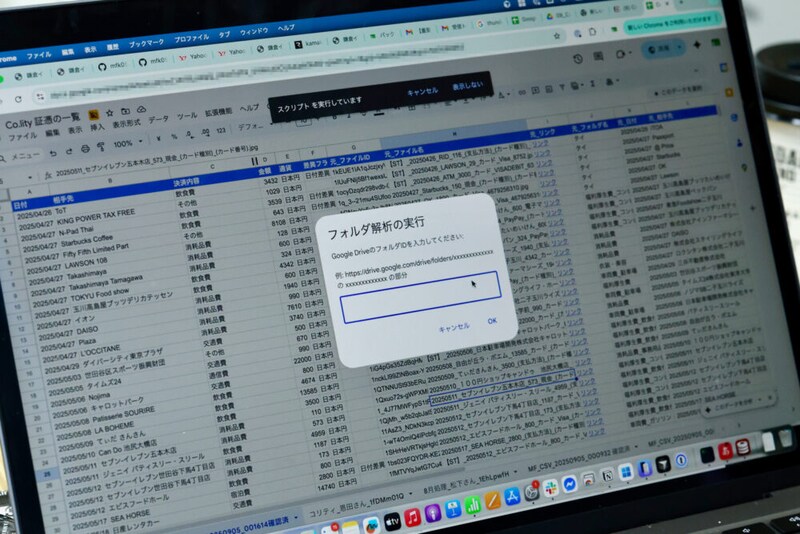
まず、ScanSnapでスキャンし、画像データとしてGoogle Driveに保存する。
この時に、ScanSnap側の設定で、
日付_相手先_金額_決済方法_カード種別_カード番号
という命名規則で、リネームする。これがかなり重要なポイント。
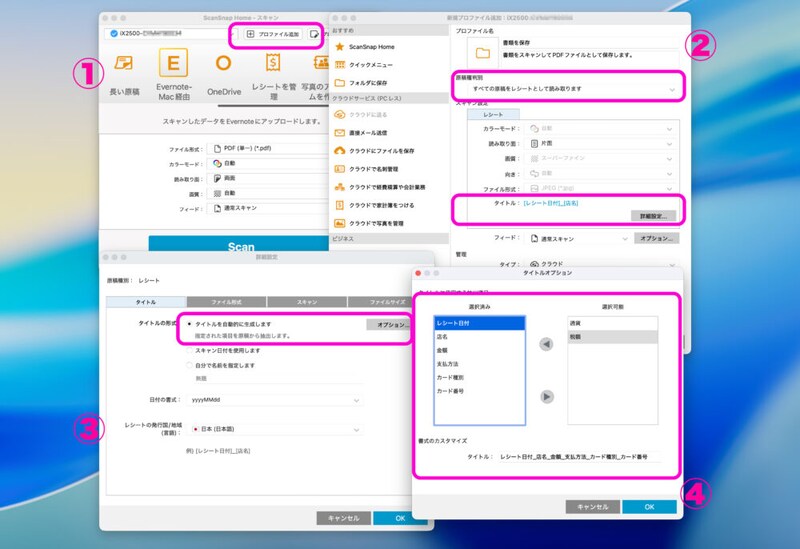
②で読み込み書類をレシートに設定すると、③〜④のように読み取ったレシートのさまざまな名称をファイル名に使える。こうやって、ScanSnapのOCRで読み取ったデータをファイル名にしてGoogle Driveに入れるのがポイントだ。
Google Driveに入れると、GAS(Google Apps Script=Googleサービス用のスクリプト言語)が使える。このGASについても、あるていど基本が分かっているなら生成AIと相談しながらコードを書けば良い。それだけで、Google Driveの中のファイルをかなり自由に扱えるようになる。
さらにGASを使って、画像ファイルの情報をスプレッドシートに展開し、構造化されたデータベースを作る。
ファイル管理情報(A~C列):ファイルID、ファイル名、ファイルへのリンク
分類情報(D列):保存フォルダ名
取引情報(E~H列):日付、相手先、金額、決済手段
カード情報(I~K列):カード種別、カード下3桁
システム情報(L~M列):最終更新日時、フォルダID
処理状況(N~O列):処理フラグ、カード種類
これで、ScanSnapのOCRが読み取った情報をGoogleスプレッドシートに展開し、さらに画像ファイルがリネームされてスプレッドシートに連携された状態が作れる。