
大きく進化した、Apple IntelligenceとSiri AIとは?
今回のWWDCの肝は、プラットフォーム全体の改良(そもそも、それはWWDC全体を指すのではないか?)、Child Account新設(これほど大きくフォーカスしたのが興味深い)、そしてSiri AIとApple Intelligenceについての3項目ということだった。
だが、まず本稿では、一番みなさんが気になるであろうSiri AIとApple Intelligenceについてご説明したい。

みなさんは、「Siriも、ChatGPTや、Geminiのようにスムーズに会話できるようになるべきだ」と思ったことはないだろうか?
どうやら、それがようやく実現しそうだ。ただし、その実現方法はChatGPTやGeminiをそのまま組み込むものではない。Appleは独自のApple Foundation Modelを中心に据えながら、Googleとの提携によってモデル性能を高める道を選んだ。
Googleの力を借りると言う文面だけを見ると、「なんだ、やっぱりアップルはAIについては遅れているんだな」と思う人もいると思うのだが、それは少々事情が違う。
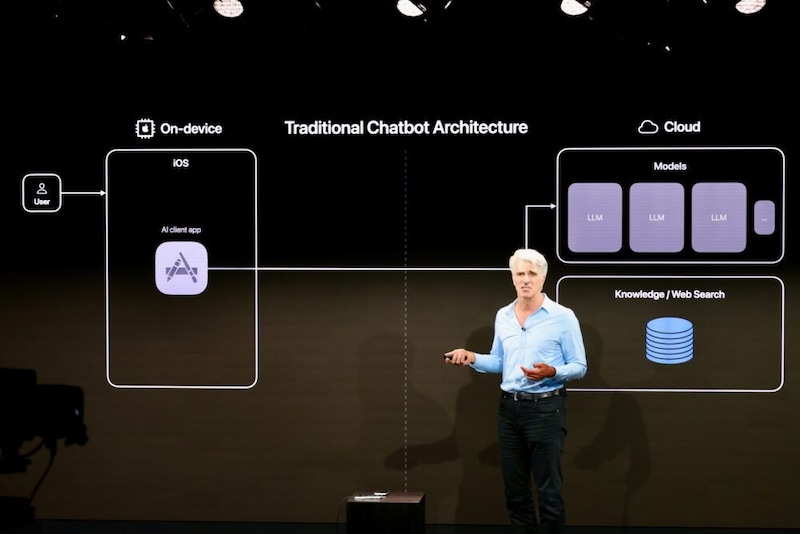
ChatGPTや、Geminiのような一般的なAIは、個人情報について少々あいまいだ。たとえば、AIを使って、かつ企業情報や個人情報を外に出さないようにするには、それらの大規模言語モデルをダウンロードして、かなり高性能なパソコンか、サーバーで動作させるしかない。たとえば、我々メディアも守秘義務のかかった発表前情報を扱う場合は、ChatGPTや、Geminiのような一般的なAIを使わないようにする必要がある。
対して、もとから『個人情報の保護』を強く謳うアップルの場合、そういった方法を使うことができなかったのだ。そこで違うカタチで動作するAIを構築する必要ががった。それさえできれば、すでに完成度の高まってるGoogleのモデルを利用する方が手早かったということだ。
そこで、まずiPhoneやMacのローカルで動く小さなモデルを開発し、その次に、もしローカルで処理できない規模の処理を扱う必要が生じた場合は、Private Cloud Computeという他社からアクセスできないエンドtoエンドで暗号化されたサーバー領域で処理するような仕組みが構築された。ここまでが、去年のWWDC 25で発表されたお話だ。
そして、今年、WWDC 26では、Apple Foundation Models(以下、AFM)とGoogle Gemini Modelsを組み合わせた、第3世代のAFMを使うと発表された。

この第3世代のモデル群には、オンデバイスで動作する『AFM Core』や『AFM Core Advanced』、およびプライベートクラウドコンピューティングで動作する『AFM Cloud』『AFM Cloud Pro』が含まれている。
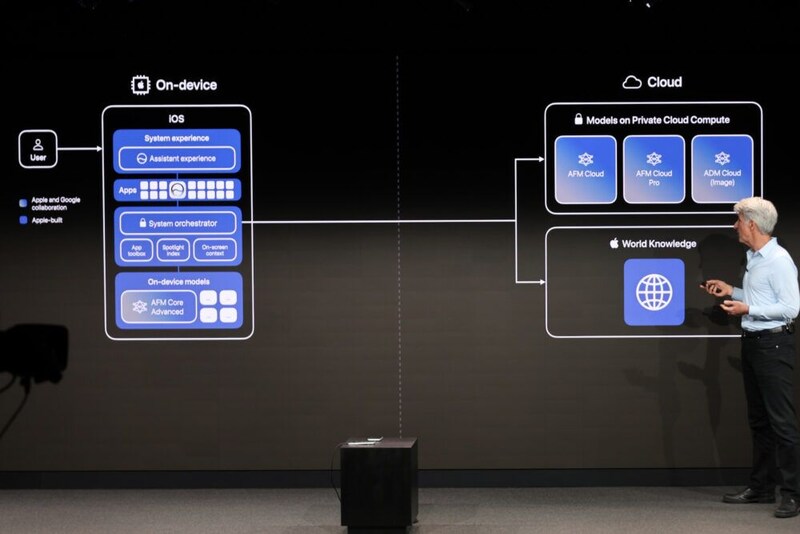
オンデバイスで動作する『AFM Core Advanced』は、なんと200億パラメータ(20B)を備えているが、スパースアーキテクチャ(sparse architecture)という仕組みを採用して、全体を常に動作させるのではなく、リクエストごとにモデルのサブセット(10〜40億パラメータ)のみを使用することで、大規模モデルのパワーと小規模モデルの低コスト・低負荷を両立させているのが特徴的。現在のApple Intelligenceで使われているAFM Coreなどは約30億パラメータということなので、これでかなり高性能になることがご理解いただけると思う。
我々の生活はどう便利になるのか? 示された実例
デモで示された例は週末のバーベキューパーティーの計画だった。
ユーザーが「みんなが持ち寄りに何を持ってくると言っていたか教えて」と尋ねると、Siri AIはメッセージやメール、メモといったデバイス内の情報を横断的に検索する。例えば「グロリアはスイカとフェタチーズの串焼きを持ってくる予定だ」といった情報を探し出し、会話形式で答えてくれる。ここで重要なのは、グロリアの情報がクラウドに送られることはなく、デバイス側で『スイカとフェタチーズの串焼き』という情報だけが抽出されることだ。
ユーザーが続けて「その料理に合う飲み物は何がいいかな」と尋ねると、Siriは直前の会話内容を理解したまま、今度は外部の知識を参照する。スイカやフェタチーズ、夏野菜のパスタといったメニューを踏まえ、「ライムとミントを加えた炭酸水が口の中をさっぱりさせる」といった提案を行う。単なる検索結果の読み上げではなく、個人の予定や会話内容と、ネット上の知識を組み合わせた推論が行われている。

プラットフォームと融合したAIのメリットはその先の便利さにある。「今の提案を参加者全員に送って」と頼めば、Siriはメールやメッセージアプリと連携し、その内容をそのまま共有できるようになる。ユーザーはアプリを切り替えたり、コピー&ペーストしたりする必要がない。情報を探し、整理し、共有するまでをひとつの会話の流れで完結させるのが狙いだ。
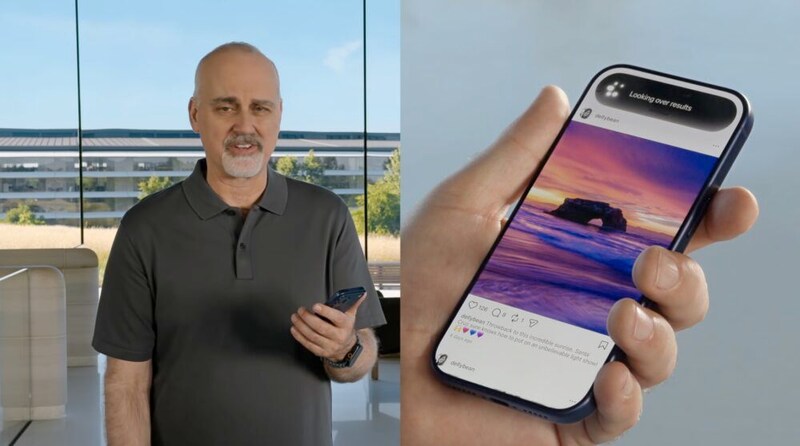
同じ考え方は画面認識やカメラ機能にも広がる。例えば風景写真を表示した状態で「ここへ行くにはどうすればいい?」と尋ねれば、Siriは画面に映っている場所を理解し、地図情報と結び付けて案内を開始する。また旅行前に機内持ち込み用バッグをカメラで映しながら「このバッグを9月のフライトに持ち込める?」と質問すれば、ユーザーの旅行予定と航空会社の規定を照らし合わせて回答する。Appleが繰り返し強調する「オンスクリーンコンテキスト」と「パーソナルコンテキスト」は、こうした体験を実現するための仕組みだ。
これらの仕組みは、iPhone、iPad、Mac、Apple Watch、Vision Proで動作する。
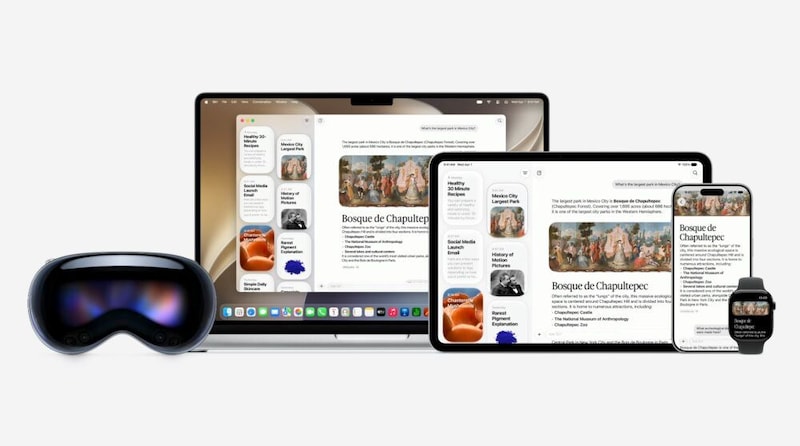
とりわけ、Vision Proの場合、ブラウザや空間に浮かぶディスプレイの表示されているものだけではなく、現実空間に見えているものまで、「このバッグを売ってるサイトを調べて」というようなカタチで聞くことができるので、また革新的な体験ができそうだ。空間に浮かぶ水晶玉のようなビジュアルも面白い。
